徐々に高度になるリングバッファの話

1. リングバッファとは何か
機能的にはFirst In First Out (FIFO)とも呼ばれるキューの一種であるが、リング状にバッファを置いてそれの中でReadとWriteのインデックスがグルグルと回る構造をとる事によって容量に上限ができることと引き換えに高速な読み書き速度を得たものである。キューを単に実装するだけなら山ほど方法があって線形リストを使ってもいいしスタックを2つ使っても原理的には可能だ。その中でもリングバッファを用いた方法の利点はひとえに性能の高さでありメモリ確保などを行わないお陰でシステム系の様々な場所で使われている。
これの実装自体は情報系の大学生の演習レベルの難度であるが少し奥が深い。まずリングバッファのスタンダードなインタフェースと実装は以下のようなものである。
class RingBuffer {
public:
explicit RingBuffer(size_t size) : buffer_(size) {}
// Returns true on success. Fails if the buffer is full.
bool enqueue(int item) {
if (write_idx_ - read_idx_ == buffer_.size()) {
return false;
}
buffer_[write_idx_ % buffer_.size()] = item;
write_idx_++;
return true;
}
// Returns true on success. Fails if the buffer is empty.
bool dequeue(int *dest) {
if (write_idx_ == read_idx_) {
return false;
}
*dest = buffer_[read_idx_ % buffer_.size()];
read_idx_++;
return true;
}
private:
std::vector<int> buffer_;
uint64_t read_idx_{0};
uint64_t write_idx_{0};
};
コンストラクタの中で配列を一つ用意し、read_idxとwrite_idxがその上をグルグル回る構図である。実装のコツとしては、インデックスの値は使用するたびに単調増加するに任せて、配列内の添字として使うときに初めてモジュロを計算して使う事でコード全体を論理的にスッキリさせることができる。初心者がやりがちなのが「バッファのサイズを超えたら0に戻して…」とif文で書く事だが、その方法でバグ無く書ききるのは意外と難しい上、read_idxとwrite_idxの値が一致した時にバッファのfull/emptyを原理的に見分けられなくなってしまうので、fullの時はwrite_idxは常にread_idxの一つ手前に居なくてはならない。言い換えると配列の全要素を使えない。0に戻さずに単調に増やし続けた場合、整数がオーバーフローする危険は一応あるが、毎秒40億回dequeueに成功し続けてもオーバーフローするのは126年後とかである。ハードウェアの限界か20**年問題の心配をしたほうが良い。マイクロベンチマークを取ってみると以下のようになった。コンパイルオプションは -O2 -DNDEBUGで、CPUはCore i7-8700 で3.2GHzである。ターボブーストは特に切ってないのでシングルスレッドならおそらく4.6GHzで回っている。
724637.68 ops/ms
72万operation/ミリ秒はスタート地点としては悪くない。perf statは以下のように言っている。
1,383.53 msec task-clock # 1.000 CPUs utilized
8 context-switches # 5.782 /sec
3 cpu-migrations # 2.168 /sec
649 page-faults # 469.090 /sec
5,953,583,928 cycles # 4.303 GHz
11,011,601,933 instructions # 1.85 insn per cycle
1,752,846,072 branches # 1.267 G/sec
1,036,980 branch-misses # 0.06% of all branches
1.85もIPCが出ているのは適当に書いたコードの割によくやっているのではなかろうか。
さて、これを高速化するのだが、まずは簡単な割に効果が大きい事としてモジュロ演算は重いのでこれをビットマスクで代用する。バッファのサイズを2の累乗のみに限定すればモジュロ演算は単純なAND演算によって等価な結果が得られる。
buffer_[write_idx_ % buffer_.size()] = item;
↑これを↓こうする
buffer_[write_idx_ & (buffer_.size() - 1)] = item;
buffer_.size()が2の冪乗である限りにおいて、-1した値は最大値以下全部のビットが立った状態になっているのでそれをマスクとして使うと最大値以上の桁上がりが消失するようになるのでモジュロと同じ効果が得られる。
性能は
1543209.877 ops/ms
154万ops/ms、倍速以上である。
2. マルチスレッド
Queueはエンキューする側Producerとデキューする側Consumerの数によって分類が可能である。
エンキュー側が1スレッドならSingle-Producer、それ以上ならMulti-Producer。
デキュー側が1スレッドならSingle-Consumer、それ以上ならMulti-Consumer。
この2x2の組み合わせで「SPMCキュー」とか「MPMCキュー」といった呼び方ができる。ここで一つ覚えて欲しいのが、SPSCの場合に限りロックなしwait-freeで実装する方法が広く知られているという事である。ロックなしで協調動作とかwait-freeとか普通なら充分身構えるべきコードであるが、SPSCキューに限って言うと「インデックスを最初に見て、操作した最後にインデックスを動かす」をエンキューとデキューの両方で実行する。ポイントはインデックスを読む時にデータの読み出しが追い越さないようにメモリバリア、インデックスを書き込む時にデータの書き込みが追い越さないようにメモリバリア。と言ってもC++は優秀なので可読性を守りながらそれなりにちゃんと書ける。
class RingBuffer2 {
public:
explicit RingBuffer2(size_t size) : buffer_(size) {}
// Returns true on success. Fails if the buffer is full.
bool enqueue(int item) {
uint64_t write_idx = write_idx_.load(std::memory_order_relaxed);
uint64_t read_idx = read_idx_.load(std::memory_order_acquire);
if (write_idx - read_idx == buffer_.size()) {
return false;
}
buffer_[write_idx & (buffer_.size() - 1)] = item;
write_idx_.store(write_idx + 1, std::memory_order_release);
return true;
}
// Returns true on success. Fails if the buffer is empty.
bool dequeue(int *dest) {
uint64_t read_idx = read_idx_.load(std::memory_order_relaxed);
uint64_t write_idx = write_idx_.load(std::memory_order_acquire);
if (write_idx == read_idx) {
return false;
}
*dest = buffer_[read_idx & (buffer_.size() - 1)];
read_idx_.store(read_idx + 1, std::memory_order_release);
return true;
}
private:
std::vector<int> buffer_;
std::atomic<uint64_t> read_idx_{0};
std::atomic<uint64_t> write_idx_{0};
};
さて見慣れない関数などが入ったので読む気は失せたと思うがloadもstoreもただ変数を読み書きするだけの関数だし、std::memory_order_*の部分は慣れるまでは読み飛ばしても構わない。こうしてメモリバリアなどが挟まったので性能はというと
646412.4111 ops/ms
64万op/msでだいぶ下がってしまっている、メモリバリアとはかくも重いものである。とは言えこれはシングルスレッドでやったからでありマルチスレッドでやると2倍のCPU資源が使えるのだから高速になることが期待できる。なので2スレッド用意して片方が5億回enqueueしてもう片方が5億回dequeueするまでにかかった時間で10億を割り算して性能を求めると。
252397.7789 ops/ms
25万!落ちている!!これは端的にはread_idx_とwrite_idx_が同じキャッシュライン(使用しているCPUでのサイズは64byte)に乗ってしまった場合に複数のコアが同一のキャッシュライン上で値を取り合ってしまうからである。論理的には別である変数を物理的に同じラインにあるからといって取り合ってしまう事をFalse Sharingと呼び、マルチスレッドの処理を書く際には頻出する問題である。対策法はいくつかあるが、
alignas(64) std::atomic<uint64_t> read_idx_{0};
alignas(64) std::atomic<uint64_t> write_idx_{0};
と書き換える事で別のキャッシュラインに乗ることを強制できる。性能を測ると
400160.064 ops/ms
40万、マシになった。複数コア間でデータをやり取りする以上オーバーヘッドは仕方ないのでここで最適化を止める道理はあるし、実際boost::lockfree::spsc_queueの実装は読む限りおよそこれに近い。
3. インデックスキャッシュ
さて、上のコードで何が問題なのかと言うとProducerはwrite_idx_、Consumerはread_idx_しかそれぞれ更新しないのに、バッファ内のempty/full判定のためにどちらも両方のキャッシュラインに触りに行ってしまう事である。IntelのCPUコアはMESIFプロトコルでキャッシュラインを共有しており、他者が書き換えたラインを読む際にはそのコアに伺いを立ててSステートに落とす必要がある。
説明に必要なキャッシュラインのステートだけ抜粋すると以下の通りである。
-
M - Modified(変更): 当該キャッシュだけに存在し、主記憶上の値から変更されている(dirty)。他のCPUがこのキャッシュラインに相当する主記憶をリードするのを許可する前に、キャッシュ機構はこのキャッシュラインをいずれかの時点で主記憶に書き戻さなければならない。
-
E - Exclusive(排他): 当該キャッシュだけに存在するが、主記憶上の値と一致している(clean)。
-
S - Shared(共有): システム内の他のキャッシュにも同じキャッシュラインが存在している(主記憶とも内容が一致)。
-
I - Invalid(無効): このキャッシュラインは無効。
データを読む時はそのアドレスに対応するキャッシュラインが存在しないかIステートだが他コアに存在する場合はSステートに変えながら自キャッシュラインにSステートで複製を作る。他コアに存在しない場合はEステートで複製を作る。
データを書く時はそのキャッシュラインがSステートなら他のコアに対して個々の複製をIステートに落とすように命じた上で自分の手元の複製をMステートに変えて書き換える。
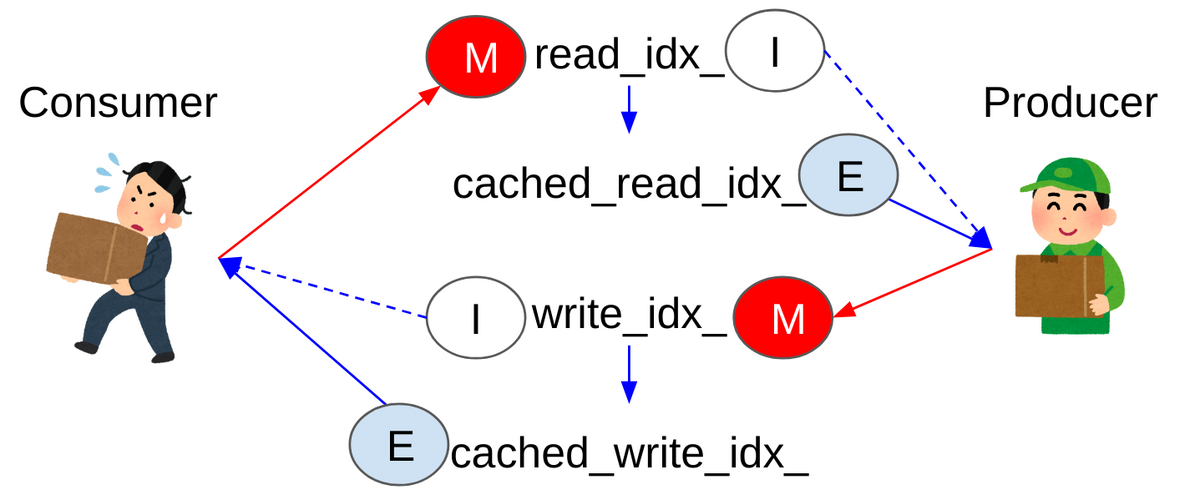
ConsumerとProducerがそれぞれ2つのキャッシュラインをMとIとSの間で書き換えてしまっている。さてここで重要な観察となるのが、キャッシュコヒーレントが衝突するほど両スレッドが活発に動いている場合、バッファが本当にfullもしくはemptyであるケースというのは比較的稀である。また、read_idx_とwrite_idx_の間が例えば100以上離れているのにread_idx_を1つ進めたからといって単調増加するwrite_idxと再度照合する必要性はない。単調増加するし自分以外がその変数に触る可能性はないという特性を活用することでさらなる高速化が見えてくる。まずキャッシュされた値を用意する。
alignas(64) std::atomic<uint64_t> read_idx_{0};
alignas(64) uint64_t cached_read_idx_{0};
alignas(64) std::atomic<uint64_t> write_idx_{0};
alignas(64) uint64_t cached_write_idx_{0};
そしてProducer側では以下のように使う。
if (write_idx - cached_read_idx_ == size_) {
cached_read_idx_ = read_idx_.load(std::memory_order_acquire);
if (write_idx - cached_read_idx_ == buffer_.size()) {
return false;
}
}
つまりread_idx_をcachedにコピーして普段はそれを使って衝突判定をし、write_idx_がcachedの方にぶち当たったら本当にバッファがいっぱいになっているかをread_idx_の実物を読みに行く事によって再度判定する。正直二度手間としか言えないコードである。だがこれによってプロデューサーが自分側でIに落ちたread_idx_のキャッシュラインのステートをSに上げに行く頻度が大きく下がる。コンシューマ側でも同様の最適化を行える。
if (cached_write_idx_ == read_idx) {
cached_write_idx_ = write_idx_.load(std::memory_order_acquire);
if (cached_write_idx_ == read_idx) {
return false;
}
}
こうすると相手がアクティブに編集する側のインデックスに対して読み出しリクエストを発行する回数が大幅に減るのでキャッシュコヒーレントトラフィック上での衝突が大いに削減できると期待できる。
性能はというと
1228501.229 ops/ms
122万!キャッシュ化前の約3倍速である。傍目には無駄な変数2つと無駄な判定と代入を足したようにしか見えないのにこのような高速化が得られる。マルチコアプログラミングの醍醐味である。
まとめ
リングバッファのようによく知られた概念であっても深掘りして高速化を追ってみるとまだまだ知らない事がいっぱいある。この記事の内容はErik Rigtorp氏の以下のブログ記事に少しアレンジを加えて追試したものである。
あちらはAMDのRyzen上で異なるCCX上のCPU間で測っているのでキャッシュコヒーレント上のペナルティがこちらより大きいため20倍速差という極端な差が出ているが、同一CPUチップ上であっても3倍速差が出るというのは興味深い知見である。マルチソケット環境ではさらなる差が出る事だろう。
今回の実験に用いたコードはMITライセンスでgist上に上げてあるので興味のある人は追試して見て欲しい。スレッドアフィニティとかHugepageとかは試したけど10%も変わらなかった。僕の実装では桁数が見やすいように分母の時間をmsにしているので、秒間あたりのスループットを見たいのであれば1000倍して欲しい。
おまけ:BingAIに「リングバッファのかっこいいイメージ図を描いて」と注文して出てきた謎の絵。

yamasaさんの指摘でメモリバリアを修正
yukiさんの指摘でコメントを修正