
この記事はデータベース・システム系 Advent Calendar 2023の2日目の記事である。前日は僕、明日も僕。
Log Structured Merge Tree(以下LSM-Tree)という物をご存知だろうか。データ構造としては順序付きの辞書であり結構昔に発明されており各操作の計算オーダーは赤黒木等と同じである。システム系学会を追っていると無限に亜種が提案されているので特徴を一言で言い表すのは難しいのだが、その一種であるLevelDBはChromiumの中でも使われている。 https://chromium.googlesource.com/chromium/src/+/HEAD/third_party/leveldatabase/leveldb_chrome.h
LSM-Treeの典型的な実装の概要とその利点・欠点を整理すると
概要
- 書き込みは常にメモリ内の辞書データ構造で受け付ける。更新も挿入も削除も常にメモリ内の辞書への挿入で完結させる。
- 削除情報は墓石(thombstone)を保存することで実現する
- ある程度書き込みが溜まったらそれをファイルに保存する。
- その際に順序付けてデータを保存する事によってファイル内での高速な探索(例えば二分探索)を可能にする。
- ファイルに保存する際に既に存在する順序データと合成して新しい順序データに統合してファイルに保存する
- 合成は単に最新の値で上書きする場合もあれば同一行の別の列への操作としてそれぞれ独立して保存するなどもできる
- 墓石で上書きされたデータは墓石になる。墓石の上からデータを書かれた場合、墓石は消える
- ファイルが大きくなってきたら一つレベルの高い辞書順データとマージ(合成)し、古い辞書順データを消す
- マージされたファイル同士も大きくなってきたら合成して最終的に定数レベルでレベル上げを打ち切る事でファイル数を定数個に抑えて探索に必要なファイル数を制限する。墓石は最高レベルのファイルには保存されない
- 読み出す際にその順序データのファイルの中に目的のものが存在しないケースが多いのでそれをいち早く検知するためにブルームフィルタを一緒に保存してメモリの中に持っておく
利点
- メモリに入り切らない総量の順序ありデータをストレージに保存しO(logN)で効率的に探索できる
- 既存のデータの状況に関わらずRandom Write (つまり辞書全体での様々な場所への書き込み)の性能がとにかく高い
- ディスクに保存する際に隙間なくデータを書き込めるのでパディングの必要がなくなり収容効率が高い
- 参考:MySQLのMyRocksストレージエンジンの話を中の人から聞いた https://qiita.com/yebihara/items/7921d3e4b5c3d3ff9215
- Write Amplify(データ一つあたりに対して内部的にwriteされる回数)が比較的少なくてディスクに優しい
- B+treeだとノードの分割や合成などで結構な回数の反復読み書きが発生している
欠点
- 検索する際にはメモリはもちろんファイルも複数スキャンする必要があり遅い
- 複数のファイルを同時にスキャンしないと正確な範囲スキャンができない
- ファイルをマージする際に多大なIO負荷がかかり応答時間が瞬間的に大きく遅れる(スパイク)
さて、これらの欠点のうち特に大きな欠点は応答時間のスパイクである。HBaseではバックエンドのストレージにLSM-treeを使っているが複製時などにスパイクが起きると同期書き込みをしている複数のレプリカが同時に待たされてユーザに対する多大な遅延として故障を疑わせるレベルで問題化するのは珍しい話ではない。
LSM-Treeの方式は様々あるが「レベルNのファイルサイズが閾値を超えたのでレベルN+1にマージする」というロジック自体が再帰的に「レベルN+1のファイルサイズが閾値を超えたのでレベルN+2にマージする」をトリガーしてしまうためマージが連鎖し、9999+1が10000になるときのように複数の繰り上がりが同時に発生し多大な遅延へと結びついてしまう。
例えばNutanixの製品の中で行われている書き込みがヘビーなワークロードだと、書き込みにかかる遅延は100万マイクロ秒、すなわち秒単位の待ち時間が発生してしまうと報告されている。ちなみにこれは書き込み遅延への最適化がある程度なされているRocksDBで起きているのである。
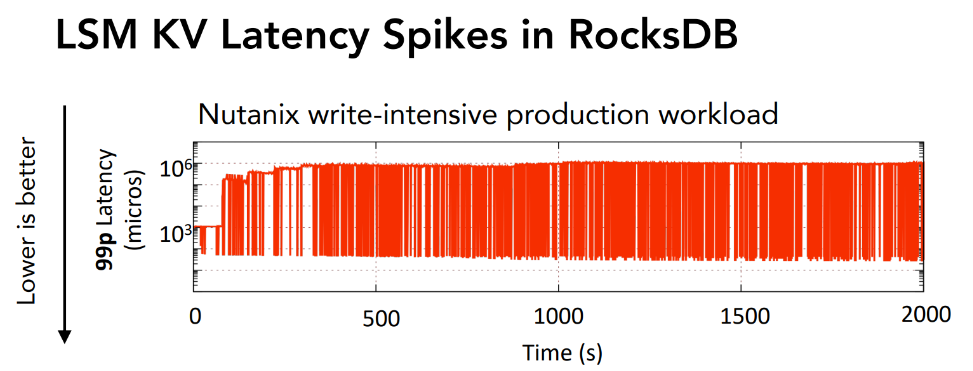
これを回避するための方法は様々提案されており
- 単一のレベルの単一の順序データも複数のファイルに分割して個別に繰り上がらせる事でマージの最悪時間を短くする(Partitioning)
- マージが連鎖して起こらないように判定を遅らせてタイミングをずらす
- 同一のレベル内でファイルをL個まで持って良い、と条件を緩和することでマージの頻度自体を下げる(Tiering)
などなどがある。
他にもL個のファイルを合成する際に単にマージソートのように編み上げていく他に複数件のファイルをバイナリーヒープで順序付けを行うことで1要素毎にファイル数に対し最大LogL回の比較で効率的にマージする方法(Tree of Loser)とかTombstoneが多いファイルから優先してコンパクションすることで容量の効率を高めたりパーティション単位で合成する際にも上のレイヤーとオーバーラップが一番小さい所から優先したり様々な工夫がある。
そしてそういう工夫をするから亜種と論文が積み上がる…。俯瞰的にはファイル数を増やせば増やすほど読むべきファイルが増えるので読み出しの性能は悪化していくが、書き込みに関してはマージの頻度やサイズを細かくできるので性能が上がる。読み取りと書き込みの性能トレードオフがあるのだが、読み取りと書き込みの性能は大量のメモリでキャッシュなりバッファなりブルームフィルタなりをすれば結構ごまかしが効く。つまりメモリ消費量ともトレードオフの関係にあり、Reference Update Memoryの3つの頭文字をとって「RUMトレードオフ」と呼ぶ。LSM Treeの話をするときはこの前提を覚えておくと立ち位置がわかって便利である。例えばLevelDBに比べてTieringを採用したRocksDBは書き込み性能に重心を寄せている、という見方ができる。論文が積み上がりすぎてて大変なのでサーベイ論文があり、LSM-based storage techniques: a surveyは良かったのでおすすめしたい。様々なレイヤーでいろんなトレードオフがあり、それを目的に合わせて組み合わせて最高のLSM-Treeを作ろうというのが潮流である。

既に公開されているLSM-Treeがどういう選択を取ったかというのはConstructing and Analyzing the LSM Compaction Design Spaceにきれいに整理されている。
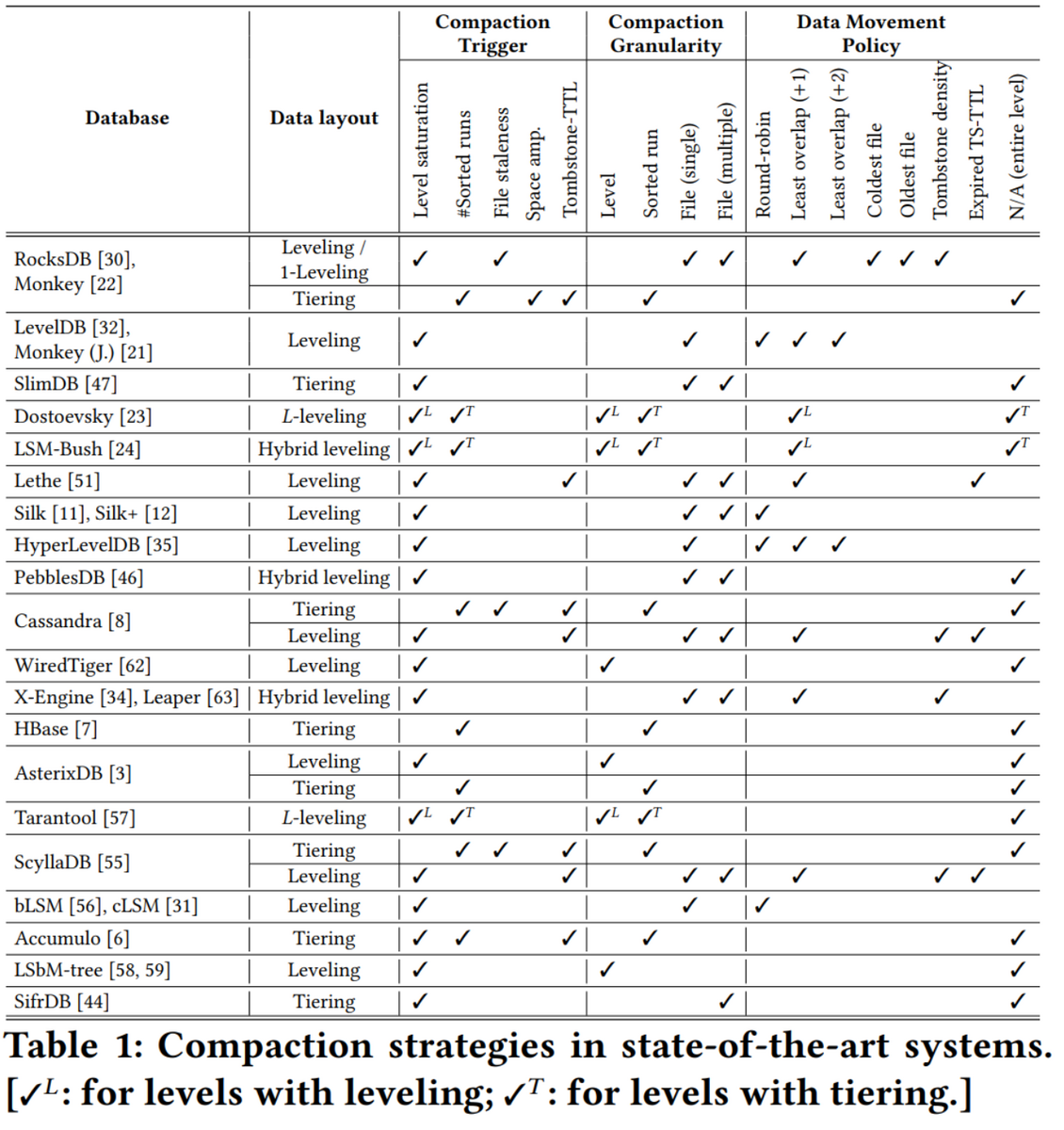
個々の最適化の詳細もまとまっており実に良い論文である。
Silk
さてそれらのトレードオフと少し違うレイヤーにいるのがバックグラウンドワーカーとそのスケジューリングである。CPUのアイドル時間という金脈を掘り起こす事で読み書きの平均性能を上げようという戦略とも言える。そこで提案されているのがSilkである。実は上のRocksDBのレイテンシのスパイクもSilkの論文から引用している。SilkはそのバックグラウンドワーカーとIOスケジューラを引っさげてレイテンシの撲滅に取り組んだLSM-Treeである。
基本戦略は以下である
- L0レベルのツリーがフルにならないようL0は優先してコンパクションを行う
- 必要に応じて高レベルのコンパクションを中断できるようにする
- 暇になったら高レベルコンパクションを行えるようにする
文章にすると簡単であるが、コンパクション処理を中断したり再開したりするのは結構めんどくさい実装が必要になりそうである。
結果としては以下のようになった
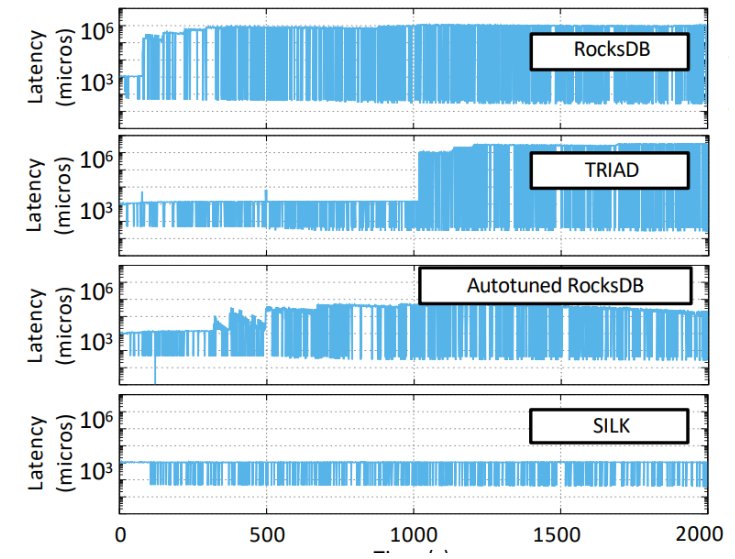
RockDBやTRIADと比べて3桁のレイテンシ短縮に成功している。しかし高レベルコンパクションが追いつかない程書き込みを流し込み続けると以下のようにSILKでもレイテンシへの悪影響は依然としてでうる。とはいえ何百秒も書き込みが連続で来る時といったらバルクロードぐらいなので普通の処理ではそんなに起きないと期待できる。
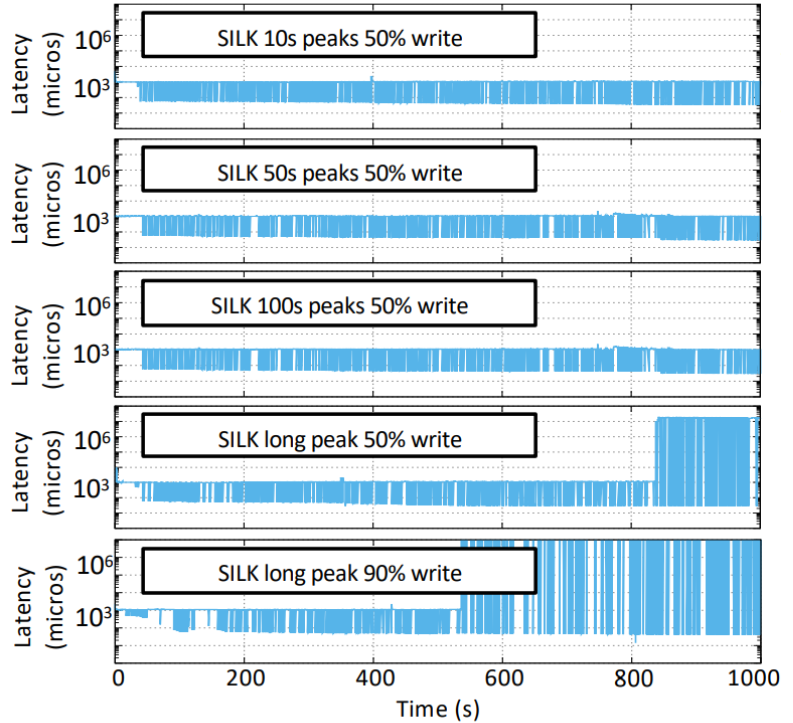
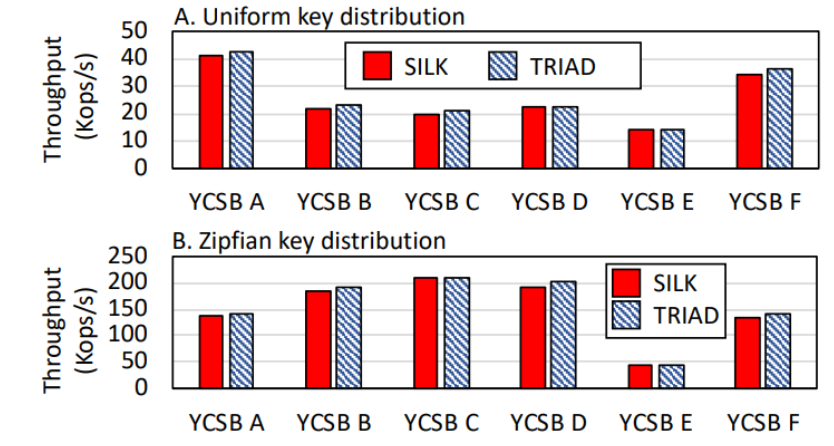
このSilkの凄いところは、レイテンシという欠点に対して結構な改善を示しながらも普通のLSM-Treeと比べてスループットでもほぼ劣らないという点である。以下の図ではTRIADというLSM-Treeと比べてもスループット面でもほぼ拮抗している様子が見て取れる。
まとめ
- LSM-Treeはよく使われている奴でも秒オーダーの書き込み遅延が発生することがある。
- その問題を解決するために色んな方法が提案されている
- Silkは中でもバックグラウンドワーカーとIOスケジューラを導入することで書き込み遅延の問題をほぼ解決した