Value Objectとは何であるか?
マーチン・ファウラーのPatterns of Enterprise Application Architecture(PofEAA)やエヴァンス・エリックのDomain Driven Design: Tackling Complexity in the Heart of Software(DDD)が原典であるが、PofEAAではこう切り出している。
When programming, I often find it's useful to represent things as a compound.
プログラミング時は物をcompound(合成物)として表現すると便利なことがしばしばある。
例えば2次元空間上での座標のように複数のメンバ(属性)を持つ物は便利である、と。しかしそれらを比較する方法は一意ではない、そこで
Objects that are equal due to the value of their properties, in this case their x and y coordinates, are called value objects.
そのプロパティ(この場合ではxとy座標)によって等価比較されるオブジェクトをvalue objectと呼ぶ。
とValue Objectの定義を行っている。そして各言語でそれぞれ比較の挙動が違う点について話が続く。
比較演算子==を用いて比較をする際、オブジェクト指向な言語の中でも挙動が変わる。JavaScriptでは {x: 1} === {x: 1} は False を返す。それら2つのオブジェクトはメモリ上で別の場所に存在する別々の物体であるとして処理され、値に基づいた比較は実施されない。Rubyでは {x:1} == {x:1} はtrueであるし、Pythonでも {'x':1} == {'x':1} はTrueを返す。Javaでも.equalsを使って比較するよう定義すれば値に基づいた等価性比較ができる。これによる良い所はどこに値の実体があるかを意識すること無く値を取り回せる点である。DBのレコードのようなIDの付いたデータの実体と、金額とか日付とか氏名といった値とを分けて考えて後者のためのオブジェクトを定義するとドメイン知識をプログラムにマッピングする際にスッキリするのが嬉しいよね、と言っている。
ドメイン次第でプリミティブな値として扱われて欲しい単位が変わるのは当然であって、CPUはそれこそ数値しか値として扱えないし、プログラム言語も文字列や複素数がプリミティブな値のように振る舞うとかがせいぜいである。しかし例えば通販のドメインであれば「注文」という概念を「店舗」というオブジェクトにメッセージとして投げつける際に添える引数の語彙は多岐に渡る。それは「顧客」や「商品」エンティティへの参照であったり「注文日」や「割引率」といった値であったり様々である。そこで、ドメインの文脈でプリミティブ型のように認識している値をオブジェクトで表現したら便利な場合もある、という話である。
だが話はここで終わらない。PofEAAの著者であるマーチン・ファウラーの説明はここで別名参照問題へと続く。早い話が「共有されたオブジェクトの状態を意図せずに変更してしまう」という問題である。
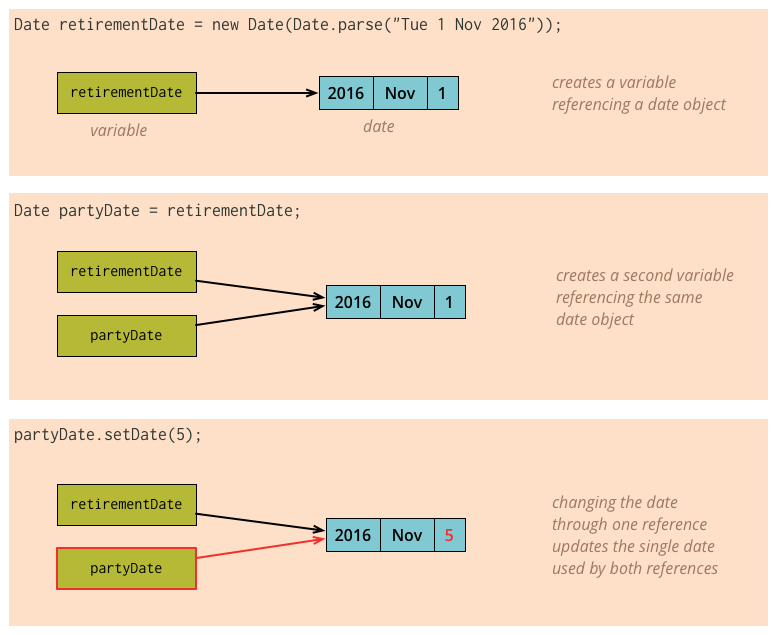
なぜこんなバグが発生するかと言うとオブジェクトが共有されてると意識せずに状態を変更してしまうプログラマの不注意が原因であって「共有を意識せよ、複製が必要ならば明示的にクローンせよ」が正論である。言葉を選ばずに言えばポインタ恐怖症によってC言語の迂回に成功しても結局の所ポインタからは逃れられていないのである。だがドメイン側の語彙としてはこれはただの値であるので値のような取り回しを前提とした書き方をしたくなるのは当然である。"="の意味する所がプリミティブ型であれば複製な一方で、オブジェクトであれば共有となるという挙動の違いは確かにややこしい。そこでマーチン・ファウラーはimmutableにすべき(should)であると言っている。
To avoid aliasing bugs I follow a simple but important rule: value objects should be immutable. If I want to change my party date, I create a new object instead.
別名参照問題を回避するために私はシンプルかつ重要なルール「Value Objectは不変であるべきである」に従っている。partyDateを変更したい時は代わりに新しいオブジェクトを作る。
つまり代入式がやることが複製なのか共有なのかを人間が都度意識するのは無駄なので「書き換える時は常に複製を作って複製物を書き換える」という解決策を取ることでこの問題を回避できると言っている。ランタイム型情報を伴う参照を通じてポリモーフィズムを実現している言語らしい解決策であるが、これはあくまで実装テクニックの一種であって、最終的な目的は「代入とは値を複製するものである」というメンタルモデルを無邪気に振り回しても事故らない環境である。現に別の実装方法にも言及している。
While immutability is my favorite technique to avoid aliasing bugs, it's also possible to avoid them by ensuring assignments always make a copy. Some languages provide this ability, such as structs in C#.
不変にするのはお気に入りの解決策であるが、代入時に常に複製にすることによっても達成可能であり、C#のstructsはそうしている。
C++でのstd::stringは内部ではヒープにメモリを確保してそこへのポインタを持ったり持たなかったりしているが、コピーコンストラクタとoperator=によって代入時の挙動が指定されており、常に複製している。結果としてstd::stringはintのように雑に代入を行っても別名参照問題は起きない(というかC++で別名参照をする時は明示的に参照やポインタを使う必要があるので、そこで事故ったのであればただのバグである)。
まとめるとValue Objectとは
- 比較がIDではなく値で行われるオブジェクトであって、ドメインの語彙として値のように振る舞うので便利。
- 複製と共有の違いをぼかしているオブジェクト指向言語ではオブジェクトを値のように振り回すと事故るので、不変性を強制する・常に複製するなどの工夫がある。
- 大事なのはプログラマのメンタルモデルをプリミティブ型の取り回しと揃える事であって、Valueのように振る舞うObjectなので"Value Object"と呼ぶ。
構造体の代入が常に複製で行われている言語(例えばC)しか使ったことない人間からすると2,3の点は有り難みを想像することすら簡単ではない。
C(++) や Rust の場合、型で不変性を制御できるといふ以前にオブジェクトの持ち方・渡し方をプログラマーが制御できるので、ドメインレベルで値の意味論を持つ概念にはそのままプログラミング言語内で値の意味論を持たせればよく、わざわざ意味論のズレを気にする必要がない
— まじかんと (@tnacigam) 2022年5月12日
ドメインをモデル化する際にはスコアとか座標とか期間とか金額といった値という概念があって、それらはIDではなく内容こそが意味を持つようにする、そして値として振る舞う事を期待するなら値のように振る舞わせるよう各自工夫しようね(工夫の大小は言語に依る)、以上の話は何もない。
一番重要なのは「値(Value)」という概念そのもの。それが複数の値の合成物からなる値ならばオブジェクトを定義してプロパティで等価比較する実装手段がいい、これをValue Objectと呼ぶ。だがオブジェクトを取り回す際には言語によっては無意識の共有操作に手を噛まれないようにせよ、回避策としてimmutableにするのもアリだよ。この順が重要である。
Java や Ruby なんかだと、言語仕様上全てのオブジェクトが参照持ち・参照渡しを強制されるので、値の意味論を持たせたいオブジェクトを扱ふには工夫が必要になる。その工夫の一つ (であって全てではない) が不変オブジェクトパターンだったりするのだが……
— まじかんと (@tnacigam) 2022年5月12日
値オブジェクトをimmutableに作るのは実装上のテクニックであって、もともとは「同一性がidentityに寄らないもの」ですよね https://t.co/pqBeob0kpG
— Masayoshi Takahashi (@takahashim) 2022年5月11日
そして実装言語依存の概念でもあることはMartin Fowlerも書いてました https://t.co/fjnPMt3UuW
Value Objectとは何でないか?
まず一番多い勘違いが「Valueを包んだObjectである」という物である。Value ObjectはValueのように振る舞うObjectであって、ValueにObjectのような振る舞いを足す事ではない。もちろんValueにObjectのような振る舞いを足すこと自体は有用なOOPの作法だがValue Objectの定義ではない。Valueを包んだObjectこと自称Value Objectの持つ条件を普通のObjectのものと区別して「単一の」「プリミティブ型を包んで」「型システムの助けを得つつ」「振る舞いを追加して」「immutableにした」ものがValue Objectであると条件を追加している人たちもいる。これは冷静に考えると上のPofEAAでの定義とは違う。
- Value Objectの出発点はそもそもcompound(合成物)であって単一の値を包めとは一言も言ってない
- プリミティブ型を包んでもID(e.g. ポインタ)で比較していたらValue Objectと呼べない
- 包まれる値はプログラム言語のプリミティブ型とは限らなくて別のValue Objectであるケースも有り得る
- ポインタやIDで比較しようが型システムの恩恵は得られるのでValue Objectに固有のアイデアではない
- クラスを定義する際に固有の振る舞いを定義するのはOOPの基本でありValue Objectに固有のアイデアではないし、Value Objectを表すクラスに常に便利なメソッドを足せとはマーチン・ファウラーも言っていない
- immutableは共有と複製の違いをぼかしたまま使うための工夫に過ぎなくて、常に複製しても良いとマーチン・ファウラーも言っている
例えばRustのNewTypeイディオムを使ってプリミティブ型を包んだクラスを作って振る舞いを定義しつつ型システムの援護を受ける事ができるが、そもそもプリミティブ型はValueそのものであるので代入がオブジェクトの共有操作と混同する危険は無いし、もっというとRustは複製と共有を厳密に区別して記述することをプログラマに求めるためまともなRust使いは混同しない。「Valueのように振る舞うObject」がValue Objectであって「Valueそのもの」の名称はValueで充分である。RustはEq traitのお陰でValueそのものを素直に定義できるバンザイ。
値にドメインに関わる特殊な挙動をさせる事を目的として例えば郵便番号とかURLとかBigDecimalクラスを定義する事自体はValue Objectの元々の発想ではない。これ単体は典型的なカプセル化の考え方で、複雑かつ外部とのインタフェースを絞れるものを閉じ込めて関心を分離するのが目的であって、IDに依らない値という概念を持つcompoundオブジェクトに値っぽい振る舞いをさせる工夫とは独立した考え方である。もちろん郵便番号クラスをValue Objectとして実装するのは順当な話であるが、それをValue Object足らしめているのは「比較のために内部の郵便番号の数値を使うオブジェクトとした事」であって「プリミティブ型を包んで振る舞いを足した事」ではない。
Value Objectの話、整理してみました。
— kawasima (@kawasima) 2022年5月11日
やってみて気づいたが、Primitive Obsessionの対策として、「Value Object」って用語を不用意に使わない方がいいな、と思いました。 pic.twitter.com/UFQKh5WZec
Value Object Obsession
観測した中で一番ひどかったのがこの勘違いである。「ドメインの語彙に数学上の概念である整数などは存在しないのですべての語彙を専用のクラスで包め」という行き過ぎた思想である。それはエンティティの全メンバーやデータベースの全列のために「顧客郵便番号」「送付先郵便番号」「事業所郵便番号」「契約日」などのクラス(メンバではなくクラス!)を定義して、immutableな振る舞いを強制する事を以てValue Objectであると言い張り、ドメイン知識の断片をそれぞれのクラスに書き散らして「高凝集になった」「型システムが守ってくれる」と喜ぶ奇行に走る。更に救えないのはこれを言語固有の問題ではなく他のプログラミング言語にも役立つプラクティスだと主張する点である。一言で言うと、DDDを誤解している。
どこが不味いかは多岐に渡るが、上に書いた「何で無いか」にことごとく当てはまりながらもそれにValue Objectという呼称を誤用しているのがまず不味い。Value Objectの提唱者自身もそんな事をしろとは言っていないし、Value Objectの実装をimmutableにして嬉しいのは共有と複製がぼかされた一部のオブジェクト指向言語に限られる。
本当にドメインの語彙上での値が専用のクラスを持つに値するほど複雑なロジックを要するのであればもちろんそれを作るべきであるが「すべての語彙をValue Objectに包む事」自体を目標にしているうちはその必要性に迫られていない。YAGNI(You ain't gonna need it)原則に従い、本当に追い出すべき複雑性が実際に現れるまでは無用なリファクタリングをすべきではない。
「個々の値を全て専用の値オブジェクトにすることによって高凝集になる」という主張はそれがかえって凝集の妨げにもなる点でも危うい。日付を持つ値オブジェクトである「発送日」「契約日」「支払い日」などのそれぞれ独立したクラスを定義した所で「存在しない日付は作れない」「未来の日付は持てない」などの原始的なバリデーションがせいぜいである。ドメインの知識を入れたら当然のように「契約日より前に発送日が設定されてはいけない」「事業所ごとのCalendarクラスが持ってる営業日内の日付しか許可しない」などの複合的な制約条件は山ほど出てくる。
OOPでも同じことで、受注金額クラスと発注金額クラスを分けるなら、それらが「金額」としては同じで、同じ制約や、文字列表現などの特性を共有し、相互変換可能であることを明らかに表明しなければならない(たぶん継承などで)。そこまでやって受注金額と発注金額を別クラスにする価値があるのか。
— 杉本啓 (@sugimoto_kei) 2022年5月11日
原理的に「値」であるプリミティブ型をわざわざクラスで包んで別名参照問題の懸念を引き起こし、更にそれをimmutableデザインによって解決する、という手順は自分で掘った穴を埋める労働のようである。「仕方なくObjectになってしまった値の振る舞いからくる問題」を解決するための手段を「初めからObjectではなかったしする必要もなかった物」に対してわざわざ適用しているという見方もできる。
Value Objectとは「ObjectがValueのように振る舞ってくれたら便利なケースもある」であって「全部のValueをObjectにしよう」でも「ValueがObjectのように振る舞うようにしよう」でもないのになぜこんな勘違いが生まれたのかというと「ThoughtWorksアンソロジー」というマーチン・ファウラーの所属する会社が書いた本に載っているというOOP Excersiseが原因ではないかと疑っている。
ルールを強制することで、いままでの自分流のコーディングとは違ったアプローチを発見することを目的としています。
(中略)
ルール3: すべてのプリミティブ型と文字列型をラップすること
これはあくまで文脈としてはOOPに慣れ親しむために大げさにOOPっぽいコードを書いてみようという練習であって、著者すらもおそらくはすべてのプログラムがこれらのルールに厳密に従うべきとは思っていない。だがこれを読んだ人が「そうか!すべての属性をラップしてそれをValue Objectと呼ぼう!」と勘違いしたというストーリーはいくばくか納得感がある。
"Primitive Obsession" を避けて "Wrap All Primitives And Strings" した結果の型を「Value Object」と呼ぶ勢力まであったのか。そら噛み合わんわな。
— yasuabe (@yasuabe2613) 2022年5月11日
僕の主観では、このOOP Excersiseの個々のルールはそれなりに納得できるものは多く、OOPっぽくリファクタリングする際の参考とする事はあるが、これに従ったコードを常に書くべきとは全く思っていない。例えば「ルール1:1 つのメソッドにつきインデントは1段階までにすること」とあって、インデントは浅いに越したことは無い点は賛同できるが例えばFizzBuzzを書くならforとifで2段のインデントで書くのが自然であって、ゴルフめいた技法でインデントを減らして可読性を下げるのは良くないし、FizzStrategyとBuzzStrategyとNumberStrategyを作り分けるStrategyFactoryと作ったAbstractStrategyの集合を管理するStrategyManagerを深いディレクトリの奥底に並べるのは冗談の域である。
そもそも問題の複雑さに合わせて膨れ上がるコードの複雑さをうまく統治するためにプラクティスを適宜使っていこうという順序で考えるべきであって、プラクティスの導入自体がコードに複雑さを加えるのであれば本末転倒である。複雑かつ巨大な仕様をコードに落とした結果として全部のメンバーがValue Objectになる事はあるかも知れないが、目的としてそれをやってはいけない。primitive obsessionはprimitive型を使い続けて実装が不必要に膨れ上がってしまった事を非難する言葉であって、primitive型を使う全てのコードが悪いわけではない。

")
アイキャッチ画像はFlickrでNichole Burrows氏の作品をCC BY 2.0に基づいて利用しています。